Topics: {% for topic in content.topic_list %} {{ topic.name }}{% if not loop.last %},{% endif %} {% endfor %}
{% endif %}ロジスティック回帰分析とは
ロジスティック回帰分析の基本概念
ロジスティック回帰分析は、統計学や機械学習の分野で広く用いられる手法です。この手法は、従属変数が二項分類(二値)の場合に使用されます。具体的には、結果が「成功」か「失敗」か、「はい」か「いいえ」かといった二つのカテゴリーのいずれかに分類される場合に適用されます。
ロジスティック回帰分析では、ある事象が発生する確率を予測するために、独立変数と従属変数の関係性をモデル化します。このモデルは、ロジスティック関数(シグモイド関数)を用いて構築されます。
ロジスティック関数の数式
ロジスティック回帰モデルは、以下の数式で表されます。
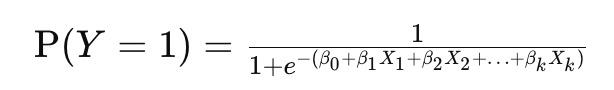
ここで、
-
P(Y=1) は従属変数
-
Y が1である確率を示します。
-
e は自然対数の底(約2.718)です。
-
𝛽0,𝛽1,𝛽2,…,𝛽𝑘はモデルの係数です。
-
𝑋1,𝑋2,…,𝑋𝑘は独立変数です。
この数式により、ロジスティック回帰モデルは、入力変数の線形結合をシグモイド関数に通すことで、0から1の間の確率値を出力します。
ロジスティック回帰の結果の解釈
ロジスティック回帰分析の結果は、オッズ比(Odds Ratio)として解釈されることが多いです。オッズ比は、ある事象が発生する確率と発生しない確率の比を示します。例えば、ある独立変数の係数が正の場合、その変数が増加すると従属変数が1になる確率が上がることを意味します。
オッズ比の計算
オッズ比は以下のように計算されます。

ここで、
𝛽𝑖は独立変数𝑋𝑖の係数です。オッズ比が1より大きければ、その変数が増加することで事象の発生確率が増加し、1より小さければ確率が減少します。
ロジスティック回帰分析と重回帰分析の違い
ロジスティック回帰分析と重回帰分析は、いずれも統計解析手法として広く用いられていますが、その目的や使用されるデータの種類に大きな違いがあります。ここでは、それぞれの手法の特徴と、具体的な違いについて詳しく説明します。
基本的な違い
従属変数の種類
-
ロジスティック回帰分析:
-
従属変数がカテゴリカル変数(主に二値)である場合に使用されます。例えば、特定の病気の有無(はい/いいえ)や、購入の有無(する/しない)などが該当します。
-
-
重回帰分析:
-
従属変数が連続変数である場合に使用されます。例えば、売上金額や気温、身長など、無限の範囲を持つ数値データを予測する際に使用されます。
-
数学的モデルの違い
ロジスティック回帰分析のモデル
ロジスティック回帰分析では、ロジスティック関数(シグモイド関数)を使用して、従属変数が1になる確率を予測します。この関数は、入力変数の線形結合を用いて確率を0から1の範囲に変換します。
重回帰分析のモデル
重回帰分析では、従属変数を独立変数の線形結合として表現します。結果として、従属変数の予測値は全ての独立変数の重み付き和として計算されます。
結果の解釈
ロジスティック回帰分析の解釈
ロジスティック回帰分析の結果は、オッズ比として解釈されます。オッズ比は、独立変数が従属変数に与える影響の大きさを示します。具体的には、ある独立変数が1単位増加することで、従属変数が「成功」(または1)になる確率がどれだけ変化するかを示します。
重回帰分析の解釈
重回帰分析の結果は、係数の値として解釈されます。各係数は、他の変数が一定であるときに、特定の独立変数が1単位増加することで従属変数がどれだけ変化するかを示します。
使用される場面の違い
ロジスティック回帰分析
ロジスティック回帰分析は、二項分類問題に適しています。例えば、以下のようなシナリオで使用されます。
-
医療診断: 患者が特定の病気にかかるリスクの予測
-
マーケティング: 顧客が製品を購入する確率の予測
-
信用評価: 借入者がローンを返済する確率の予測
重回帰分析
重回帰分析は、連続データの予測に適しています。例えば、以下のようなシナリオで使用されます。
-
売上予測: 広告費用や季節変動を考慮した売上高の予測
-
不動産評価: 物件の特徴に基づく市場価値の予測
-
経済分析: 経済指標に基づくGDPや失業率の予測
モデルの評価方法の違い
ロジスティック回帰分析
ロジスティック回帰分析では、モデルの性能を評価するために以下のような指標が使用されます。
-
正答率(Accuracy)
-
再現率(Recall)
-
適合率(Precision)
-
ROC曲線とAUC(Area Under Curve)
重回帰分析
重回帰分析では、モデルの性能を評価するために以下のような指標が使用されます。
-
決定係数(R²)
-
平均二乗誤差(MSE)
-
平均絶対誤差(MAE)
ロジスティック回帰分析のメリット
ロジスティック回帰分析は、統計解析や機械学習の分野で非常に有用な手法です。その多くのメリットにより、さまざまな分野で広く利用されています。ここでは、ロジスティック回帰分析の主なメリットについて詳しく説明します。
1. 分類問題への適用性
ロジスティック回帰分析は、二項分類問題に特化しており、対象が二つのカテゴリーに分類される場合に最適な手法です。例えば、顧客が製品を購入するか否か、患者が病気にかかるか否かなど、明確に二分できる問題に適用できます。
2. 結果の解釈が容易
ロジスティック回帰分析の結果はオッズ比として解釈されます。オッズ比は、ある独立変数が1単位増加することで従属変数の事象が発生する確率がどれだけ変わるかを示します。この直感的な解釈ができるため、非専門家にも理解しやすいです。
オッズ比の具体例
例えば、マーケティングの文脈で「メールマーケティングキャンペーン」の効果を評価する場合、オッズ比が2であるとすると、メールを受け取った顧客が製品を購入する確率は、メールを受け取っていない顧客の2倍になることを意味します。
3. モデルの汎用性と柔軟性
ロジスティック回帰分析は、独立変数が連続変数であってもカテゴリカル変数であっても対応可能です。また、相互作用項や非線形項を含めることで、複雑な関係性をモデルに取り入れることができます。この柔軟性により、様々な現実の問題に適用できます。
例: 交互作用項の追加
例えば、広告の影響を評価する場合、広告費用と季節変動の相互作用項を含めることで、特定の季節における広告効果をより正確に予測できます。
4. モデルの評価と選択が容易
ロジスティック回帰分析では、モデルの評価に使用される指標が豊富であり、これによりモデルの適合性や予測力を簡単に評価できます。代表的な指標には、ROC曲線やAUC(Area Under Curve)、正答率、適合率、再現率などがあります。
ROC曲線とAUC
ROC曲線は、分類モデルの性能を評価するための視覚的ツールであり、AUCはこの曲線の下の面積を示します。AUCが1に近いほど、モデルの予測精度が高いことを意味します。
5. 計算効率が高い
ロジスティック回帰分析は計算効率が高く、大規模なデータセットでも迅速に計算を行うことができます。これにより、ビッグデータを扱う現代のデータサイエンスにおいても有効な手法となっています。
6. 異常値に対する頑健性
ロジスティック回帰分析は、データセット内の異常値(アウトライヤー)の影響を比較的受けにくい特徴があります。これは、モデルが確率の予測を行うため、極端な値が予測結果に大きな影響を与えにくいからです。
ロジスティック回帰分析の注意点
ロジスティック回帰分析は強力な手法ですが、その使用にはいくつかの注意点があります。これらの注意点を理解し、適切に対処することで、より正確で信頼性の高い結果を得ることができます。
1. 仮定の確認
線形関係の仮定
ロジスティック回帰分析では、独立変数と従属変数の間に線形関係があると仮定しています。つまり、独立変数の線形結合がロジスティック関数に対して適切にフィットする必要があります。この仮定が満たされない場合、モデルの予測精度が低下する可能性があります。
多重共線性の回避
独立変数間に高い相関があると、多重共線性の問題が生じます。多重共線性が存在すると、係数の推定が不安定になり、解釈が難しくなります。この問題を回避するためには、変数選択や主成分分析(PCA)などの方法を用いて、相関の高い変数を除外することが重要です。
2. データの前処理
データのスケーリング
独立変数のスケールが大きく異なる場合、モデルの収束が遅くなることがあります。標準化や正規化を行い、変数のスケールを揃えることで、この問題を解決できます。
欠損値の処理
欠損値が存在する場合、そのままではモデルの学習に悪影響を及ぼします。欠損値は適切に処理する必要があります。一般的な方法としては、欠損値のある行を除外する方法、平均値や中央値で補完する方法があります。
3. データのバランス
不均衡データの影響
従属変数のカテゴリが不均衡である場合、モデルは頻度の高いカテゴリに偏る傾向があります。例えば、クラス0が90%、クラス1が10%の場合、モデルはクラス0を優先して予測しがちです。この問題を解決するためには、データのバランスを取る方法(例:オーバーサンプリングやアンダーサンプリング)を用いることが有効です。
4. モデルの評価
適切な評価指標の選択
モデルの評価には、適切な指標を選択することが重要です。正答率だけでなく、適合率、再現率、F1スコアなども併せて評価することで、モデルの性能を総合的に判断できます。
クロスバリデーションの実施
モデルの過学習を防ぐために、クロスバリデーションを行うことが推奨されます。クロスバリデーションにより、モデルの汎化性能を評価でき、データの分割によるバイアスを軽減できます。
5. 解釈の注意点
オッズ比の解釈
オッズ比は、独立変数が1単位変化したときの従属変数のオッズの変化を示しますが、その値が統計的に有意であるかどうかを確認する必要があります。信頼区間やp値をチェックすることで、オッズ比の信頼性を評価できます。
ロジスティック回帰分析の活用シーン
ロジスティック回帰分析は、その柔軟性と解釈のしやすさから、多くの分野で広く利用されています。以下に、代表的な活用シーンをいくつか紹介します。
1. 医療分野
疾病予測と診断
ロジスティック回帰分析は、患者が特定の病気にかかるリスクを予測するために使用されます。例えば、患者の年齢、性別、生活習慣などのデータを基に、心疾患や糖尿病の発症リスクを評価します。このような予測モデルは、早期診断や予防策の立案に役立ちます。
治療効果の評価
治療法の効果を評価する際にも、ロジスティック回帰分析が使用されます。特定の治療を受けた患者が回復する確率を予測し、治療法の有効性を評価することで、医療現場での意思決定を支援します。
2. マーケティング分野
顧客行動の予測
マーケティングでは、ロジスティック回帰分析を用いて顧客の購買行動を予測します。例えば、過去の購入履歴やウェブサイトの閲覧履歴を基に、特定の製品を購入する確率を算出します。この情報を活用して、ターゲット広告やプロモーション戦略を最適化することができます。
チャーン予測
顧客がサービスを解約する確率を予測するためにも、ロジスティック回帰分析が用いられます。顧客の利用状況やサポート問い合わせ履歴を基に、チャーンリスクの高い顧客を特定し、適切な対応策を講じることで、顧客離れを防ぐことができます。
3. 金融分野
クレジットリスク評価
金融機関では、クレジットリスクを評価するためにロジスティック回帰分析を使用します。借入申請者の収入、信用履歴、雇用状況などのデータを基に、貸し倒れリスクを予測します。これにより、貸付判断の精度を向上させ、リスク管理を強化することができます。
不正検出
クレジットカードの不正使用を検出するためにも、ロジスティック回帰分析が役立ちます。取引データを解析し、不正の可能性が高い取引を特定することで、迅速な対応を可能にします。
4. 人事分野
採用予測
企業の採用プロセスにおいて、候補者の適性を予測するためにロジスティック回帰分析が使用されます。応募者の履歴書や面接評価を基に、採用後のパフォーマンスを予測し、最適な人材を選定するのに役立ちます。
従業員の離職予測
従業員の離職リスクを予測するためにも、この手法が利用されます。従業員の勤務年数、昇進履歴、勤務態度などのデータを分析し、離職の可能性が高い従業員を特定して、早期に対策を講じることができます。
5. 公共政策分野
社会問題の予測と対策
ロジスティック回帰分析は、犯罪発生率や交通事故の発生リスクを予測するために活用されます。地域の特徴や過去のデータを基に、リスクの高い地域や時間帯を特定し、効果的な対策を講じることができます。
選挙結果の予測
選挙においても、ロジスティック回帰分析は有効です。候補者の支持率や有権者の属性データを基に、選挙結果を予測し、選挙戦略の立案に役立てることができます。
まとめ
ロジスティック回帰分析は、分類問題に特化した強力な統計手法です。この記事では、その基本概念やメリット、重回帰分析との違い、注意点、活用シーンについて詳しく解説しました。ロジスティック回帰分析を効果的に活用するためには、データの前処理やモデルの評価方法に注意を払い、適切な仮定の下でモデルを構築することが重要です。様々な分野での実用例を参考に、データ駆動型の意思決定に役立ててください。

株式会社Srushのマーケティング担当者。 豊富な営業経験を経て、顧客の認知から購入に至るプロセスにおける要素分析の難しさに直面し、その解決策としてSrushとの出会いを果たす。 データ分析の力を駆使して、日本の全企業がより効果的な意思決定を行い、競争力を高めるためのパートナーでありたいと思っています。趣味はカフェ巡り